

本文目录一览:
人工智能模型数据泄露的攻击与防御研究综述
1、人工智能模型数据泄露的攻击类型基于模型输出的数据泄露 模型窃取攻击:攻击者通过与模型的交互,利用模型的输出结果来窃取模型的参数或结构信息。这种攻击方式不需要直接访问模型的内部数据,而是通过观察模型的输入输出行为来推断模型的内部状态。模型逆向攻击:攻击者利用模型的输出结果等信息,反向推导出用户的隐私数据。
2、人工智能作为网络安全威胁的体现社会工程攻击的升级威胁行为者利用生成式人工智能(如大型语言模型)创建高度逼真的钓鱼邮件、虚假语音或视频,绕过传统检测机制。例如,AI可模仿人类写作风格生成针对性钓鱼内容,或通过深度伪造技术伪造高管指令,诱导员工泄露敏感信息。

3、方案背景与核心威胁LLM作为基于海量数据训练的深度学习模型,其应用场景涵盖私有化部署、公共SaaS服务及独立产品形态,但面临以下安全威胁:传统Web攻击:XSS、SQL注入等攻击可通过HTTP/HTTPS协议直接威胁LLM应用。新型场景化攻击:提示词攻击:通过恶意输入操纵模型输出,导致数据泄露或生成违规内容。

用于对机器学习模型进行对抗性攻击、防御和基准测试的Python库:CleverHa...
1、CleverHans 0.0 是一个用于机器学习模型对抗性攻击、防御和基准测试模型对抗攻击防御的 Python 库模型对抗攻击防御,由 Google Brain 的 Ian Goodfellow 和 Nicolas Papernot 管理和维护,版权归 2018 年 Google Inc.、OpenAI 和宾夕法尼亚州立大学所有。
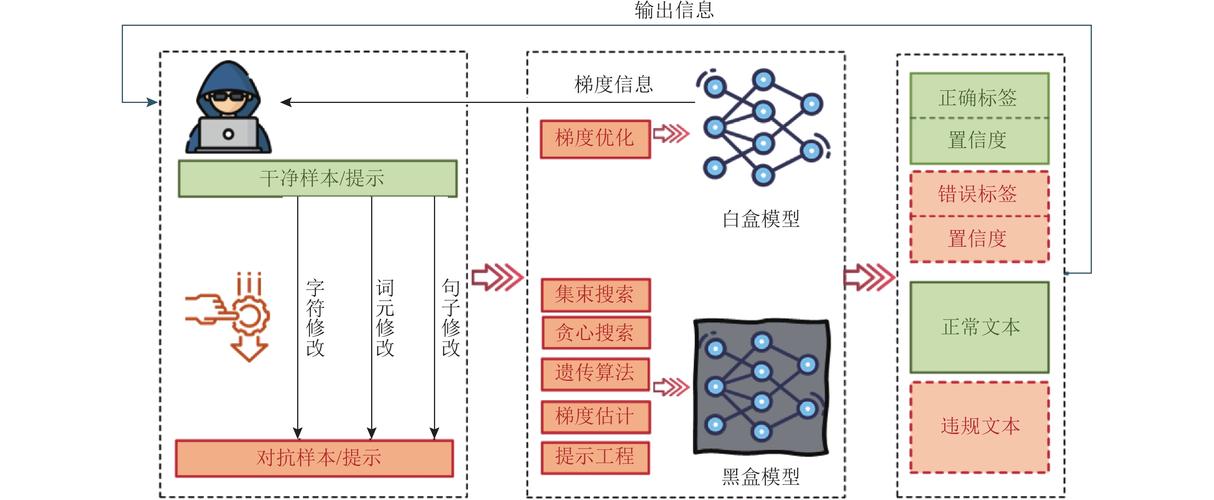
2、对抗性攻击的原理是通过设计特定的数值型向量(即对抗样本),使机器学习模型产生误判。其核心在于利用模型输入的数值特性及内部决策机制的脆弱性,构造看似正常却能欺骗模型的输入数据。

3、Adversarial Robustness 360(ART)Toolbox简介:一个用于保障机器学习安全性的Python库,旨在帮助AI防御对抗性攻击。功能:评估与保护:提供工具让研发人员能够根据各种对抗性威胁(包括逃避、中毒、提取和推断)来评估、保护、证明和验证机器学习模型和应用程序。
了解对抗性机器学习:攻击与防御的全面解析
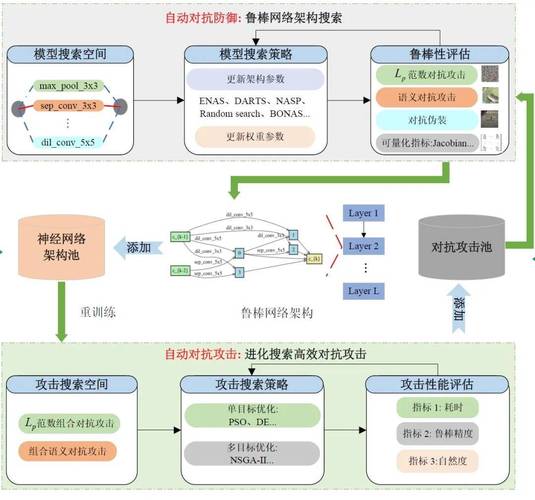
1、优点是能击败多数防御机制(如对抗训练),缺点是计算成本极高。生成对抗网络(GAN):通过生成器与鉴别器的博弈生成对抗样本。优点是样本多样性高,缺点是训练不稳定且需大量计算资源。零阶优化攻击(ZOO):无需模型内部信息,通过查询目标模型估计梯度。优点是适用于黑盒场景,缺点是需大量查询,可能暴露攻击行为。
2、对抗性机器学习是对攻击者用来攻击机器学习(ML)系统的一系列手段的统称,其利用了ML模型的漏洞和特殊性实施攻击,对网络空间安全构成重大威胁,以下从威胁与防御两方面进行介绍:威胁方面:对抗性机器学习攻击分为中毒攻击、逃避攻击、提取攻击和推理攻击四种方式。
3、对抗性攻击的原理是通过设计特定的数值型向量(即对抗样本),使机器学习模型产生误判。其核心在于利用模型输入的数值特性及内部决策机制的脆弱性,构造看似正常却能欺骗模型的输入数据。
4、对抗攻击学习:来自人类的恶意攻击 对抗攻击学习,或称对抗性机器学习,是指攻击者通过精心构造的输入数据来欺骗机器学习模型,使其产生错误的输出。这种攻击方式在深度神经网络中尤为显著,因为深度神经网络虽然在很多任务上表现出色,但也被证明极易受到对抗性扰动的影响。
5、对抗性学习技术的核心解析 对抗性学习的定义与目标对抗性学习是一种通过引入对抗性样本提升模型鲁棒性的机器学习技术。其核心目标是通过主动生成具有挑战性的数据,迫使模型在训练阶段暴露并修正弱点,从而增强对现实数据分布变化的适应性。
6、机器学习的最强敌人是“对抗性机器学习攻击”,这类攻击通过特定输入方法使模型行为失常,暴露了机器学习模型在安全性上的核心脆弱性。具体分析如下:对抗性机器学习的工作原理机器学习模型通过训练阶段构建,随后部署于新数据。例如,通过输入可食用与不可食用蘑菇的照片训练模型,以识别森林中的蘑菇是否安全。







